
二叉树基础结构及其遍历
二叉树结构及其遍历
力扣上对二叉树的链式代码实现:
1 | //Definition for a binary tree node. |
递归遍历与层序遍历是二叉树的两种遍历方式,也分别对应了经典暴力搜索算法中的DFS算法与BFS算法。
递归遍历
基本模板:
1 | void RecursionTraverse(TreeNode *root ){ |
效果:进入根节点后一直往左节点走,直到遇到空指针后,返回上一层的父节点并执行父节点的RecursionTraverse(root->right)并以此往复。
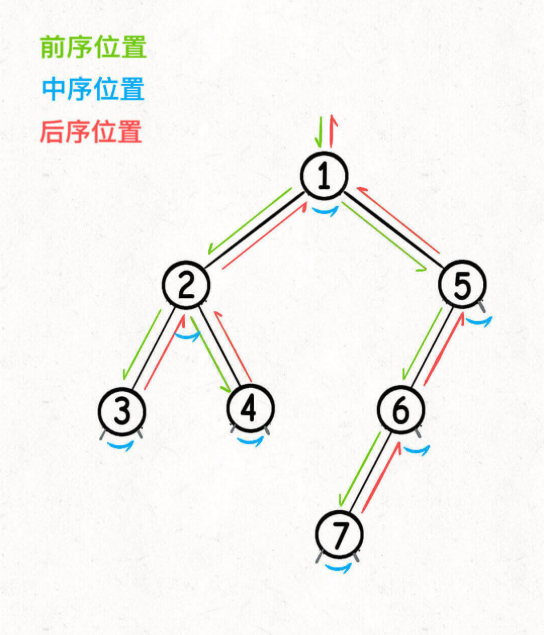
Note:递归遍历节点的顺序仅取决于左右子节点的递归调用顺序,与其他代码无关。
与所谓的前、中、后序遍历的区别是,前中后序遍历的结果不同,原因是因为把代码写在了不同位置,所以产生了不同的效果。而这与递归函数(上述模板)本身如何实现没有关系。
总结:在两行RecursionTraverse递归调用的相对顺序不变的情况下,函数本身访问节点的顺序不变,而在前、中、后序插入代码位置改变的是对应代码的执行顺序。
By the way,个人认为理清这个递归遍历的过程能够很好地帮助理解递归算法,
前、中、后顺序对应的也就是
•代码在刚进入节点(还未进行进一步递归)
•节点的递归完成一半(左子树已遍历完成)
•节点的递归完成(左右字树都已完成,准备弹出当前节点的值)
这三个时机
层序遍历
对于初学者来说,层序遍历的顺序比较直观,即在一层从左到右遍历,直到遍历完后再进入下一层,以此往复。
效果:每次进入一个节点,将当前节点从队头移出,并把该节点的左右子节点(若存在)加入队尾。
基本模板:
1 | void LevelOrderTraverse(TreeNode *root){ |
如果涉及到每条树枝的权重不同,要求遍历后输出每个节点对应的路径权重和,则不能仅设置一个“全局”的depth变量了。
此时可以创建一个新的类State:
1 | class State{ |
然后队列从存储TreeNode指针改为存储State,以便每个节点单独维护自己的路径权重和即可,其余代码逻辑基本不变。
最后
二叉树的递归遍历和层序遍历就是最简单的 DFS 算法和 BFS 算法,在实际的算法问题中,DFS 算法常用来穷举所有路径,BFS 算法常用来寻找最短路径。
在“找出二叉树的最小深度”问题中,由于递归遍历要碰到叶子节点,必然要经过所有节点才能判断;而BFS 逐层遍历的逻辑,第一次遇到目标节点时,所经过的路径就是最短路径,算法可能并不需要遍历完所有节点就能提前结束,从而效率相对更高。
而在“穷举所有路径”问题中,由于递归遍历的顺序就是天然地按照一条条树枝走下去的,每次遇到叶子节点就能记录一条路径,逻辑上是互通自洽的,因此DFS算法的代码一般来说更为简洁。